Hi!
I’m developing a 3d game for mobile with creator 3.0. I’m having a hard time understanding what configuration related to rendering is available and needed to consider when building a game for android.
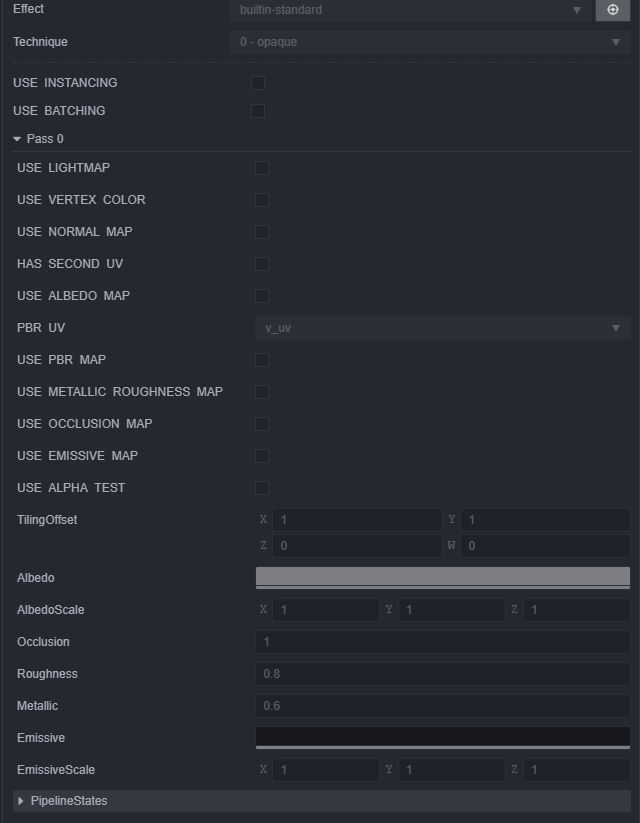
The scenario here to illustrate the problem is a game with a simple scene filled with 100 boxes using default box mesh and materials. The scene does not have dynamic lights.
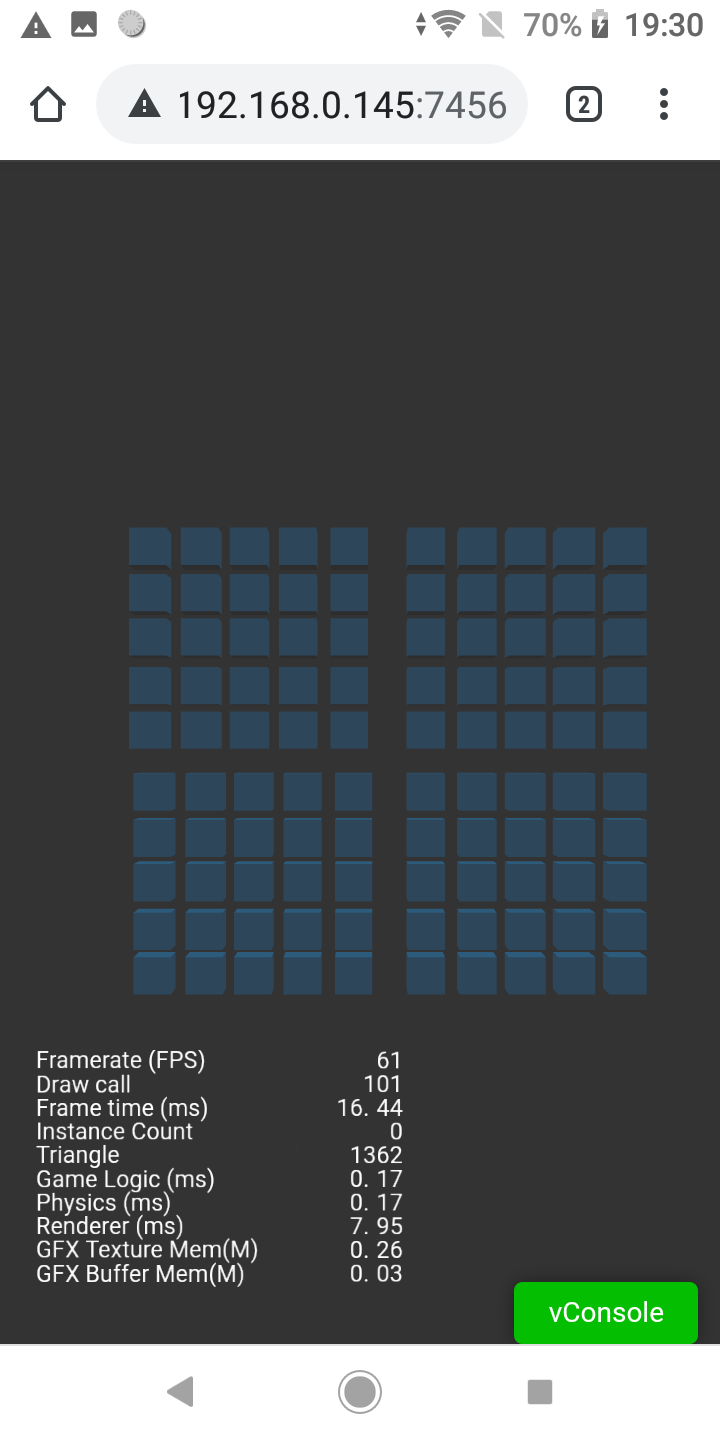

The issue I’m having is that in preview or mobile web build the rendering time based on the debug info is about half than in android build. If batching is used the overall performance gets better as expected but the difference between the builds grows.
Is there any material available or any tips that could help understand where this kind of difference in performance could be coming from?
Test project if needed: GitHub - migguli/cocos-boxtest